# node 操作文件
基本的处理文件:
const fs = require('fs')
const path = require('path')
const fileName = path.resolve(__dirname, 'data.txt')
// 读取文件内容--一次性读取所有的数据
fs.readFile(fileName, (err, data) => {
if(err) {
console.error(err)
return
}
// data 是二进制类型,需要转换为字符串
console.log(data.toString())
})
// 写入文件
const content = '写入的内容\n'
const opt = {
flag: 'a' // 追加写入,覆盖用 'w'
}
fs.writeFile(fileName, content, opt, (err) => {
if(err) {
console.error(err)
}
})
// 判断文件是否存在
fs.exists(fileName, (exist) => {
console.log('exist', exist)
})
# 文件 IO 操作的性能瓶颈
stream 方式进行读取文件,如下图:
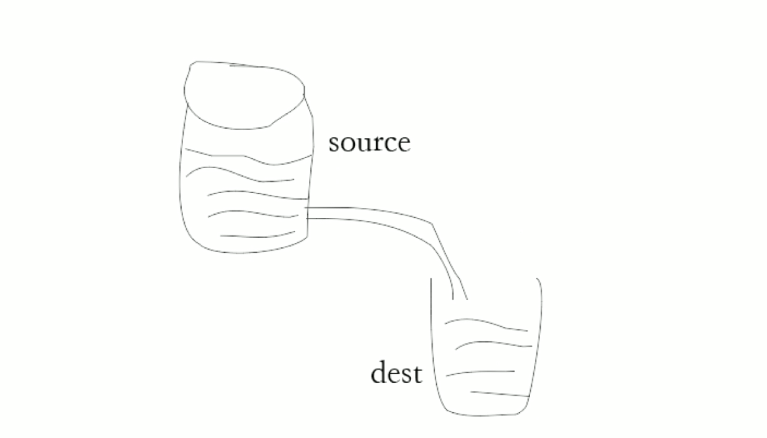
我们上面的一次性读取文件中如果的内容,就相当于直接将 source 的一桶水倒到了 dest 中,这样会很消耗性能;通过 stream 的方式,就类似图上,连接一个管道,慢慢的进行接收数据。
node 中获取 postData 数据的时候,也是用到了这种 stream 方式去获取到客户端发过来的数据:
const promise = new Promise((resolve, reject) => {
let postData = ''
// 接收到部分数据
req.on('data', chunk => {
postData += chunk.toString()
})
// 监听数据接收完成
req.on('end', () => {
if(!postData) {
resolve({})
return
}
resolve(
JSON.parse(postData)
)
})
})
return promise
}
# stream 演示
// 管道接收数据
const http = require('http')
const server = http.createServer((req, res) => {
if(req.method === 'POST') {
req.pipe(res)
}
})
server.listen(8000)
// 复制文件
const fs = require('fs')
const path = require('path')
const fileName1 = path.resolve(__dirname, 'data.txt')
const fileName2 = path.resolve(__dirname, 'data-bak.txt')
// 读取文件的 stream 对象
const readStream = fs.createReadStream(fileName1)
// 写入文件的 stream 对象
const writeStream = fs.createWriteStream(fileName2)
// 执行拷贝,通过 pipe
readStream.pipe(writeStream)
// 监听每次读取的内容
readStream.on('data', chunk => {
console.log(chunk.toString(), '***********')
})
// 读取完成
readStream.on('end', () => {
console.log('copy done')
})
// http 请求返回文本数据 文件 IO 以及网络 IO
const fs = require('fs')
const path = require('path')
const http = require('http')
const fileName1 = path.resolve(__dirname, 'data.txt')
const server = http.createServer((req, res) => {
if(req.method === 'GET') {
const readStream = fs.createReadStream(fileName1)
readStream.pipe(res)
}
})
server.listen(8000)
# 实践 node 写日志
const fs = require('fs')
const path = require('path')
// 写日志
function writeLog(writeStream, log) {
writeStream.write(log + '\n')
}
// 生成 write Stream
function createWriteStream(fileName) {
const fullFileName = path.join(__dirname, '../', '../', 'logs', fileName)
const writeStream = fs.createWriteStream(fullFileName, {
// 追加
flags: 'a'
})
return writeStream
}
// 写访问日志
const accessWriteStream = createWriteStream('access.log')
function access(log) {
writeLog(accessWriteStream, log)
}
// 写报错日志
const errorWriteStream = createWriteStream('error.log')
function errorLog(log) {
writeLog(errorWriteStream, log)
}
// 写事件日志
const eventWriteStream = createWriteStream('event.log')
function eventLog(log) {
writeLog(eventWriteStream, log)
}
module.exports = {
access,
errorLog,
eventLog
}
使用:
const http = require('http')
const PORT = 8000
const { access } = require('./src/utils/log.js')
const serverHandle = require('../app')
const server = http.createServer((req, res) => {
// 记录 access log
access(`${req.method} -- ${req.url} -- ${req.headers['user-agent']} -- ${Date.now()}`)
})
server.listen(PORT, () => {
console.log('server listen on localhost:8000')
})
# 日志的拆分
如果我们一直在一个文件中写日志,日志内容会慢慢累积,放在一个文件不好处理,可以按照时间划分日志文件,比如 2020-07-04.access.log ,我们可以通过 linux 的 crontab 命令,即定时任务。
# crontab
*代表:分钟小时日期月份星期
- 设置定时任务,格式:*****command
- 将 access.log 拷贝并重命名为 2020-07-04.access.log
- 清空 access.log 文件,继续积累日志
使用 crontab 执行的脚本
# 执行文件
#!/bin/sh
cd F:\myGithub\node-blog\logs
cp access.log $(date +%Y-%m-%d).access.log
echo "" > access.log
# 日志分析
使用 node 的 readline(基于 stream)来读取日志文件进行分析:
下面代码是读取上面生成的 access.log 日志,来分析 chrome 的占比:
const fs = require('fs')
const path = require('path')
const readline = require('readline')
// 文件名
const fileName = path.join(__dirname, '../', '../', 'logs', 'access.log')
// 创建 read stream
const readStream = fs.createReadStream(fileName)
// 创建 readline 对象
const rl = readline.createInterface({
input: readStream
})
let chromeNum = 0
let sum = 0
// 逐行读取
rl.on('line', lineData => {
if(!lineData) {
return
}
// 记录总行数
sum ++
const arr = lineData.split(' -- ')
if(arr[2] && arr[2].indexOf('Chrome') > 0) {
// 累加 chrome 的数量
chromeNum ++
}
})
// 监听读取完成
rl.on('close', () => {
console.log('chrome 占比:' + chromeNum / sum)
})
阅读量: