# DOM2、DOM3
DOM1(DOM Level 1)主要定义了 HTML 和 XML 文档的底层结构。DOM2(DOM Level 2)和 DOM3(DOM Level 3)在这些结构之上加入更多交互能力,提供了更高级的 XML 特性。实际上,DOM2 和 DOM3 是按照模块化的思路来制定标准的,每个模块之间有一定关联,但分别针对某个 DOM 子集。 这些模式如下所示。
- DOM Core:在 DOM1 核心部分的基础上,为节点增加方法和属性。
- DOM Views:定义基于样式信息的不同视图。
- DOM Events:定义通过事件实现 DOM 文档交互。
- DOM Style:定义以编程方式访问和修改 CSS 样式的接口。
- DOM Traversal and Range:新增遍历 DOM文档及选择文档内容的接口。
- DOM HTML:在 DOM1 HTML 部分的基础上,增加属性、方法和新接口。
- DOM Mutation Observers:定义基于 DOM变化触发回调的接口。这个模块是 DOM4 级模块,用于取代 Mutation Events。
# DOM 变化
# DocumentType 类型的变化
DocumentType 新增了 3 个属性: publicId 、 systemId 和 internalSubset 。 publicId 、systemId 属性表示文档类型声明中有效但无法使用 DOM1 API 访问的数据。比如下面这个 HTML 文档类型声明:
<!DOCTYPE HTML PUBLIC "-// W3C// DTD HTML 4.01// EN""http://www.w3.org/TR/html4/strict.dtd">
其 publicId 是 "-// W3C// DTD HTML 4.01// EN" ,而 systemId 是 "http://www.w3.org/TR/html4/strict.dtd" 。支持 DOM2 的浏览器应该可以运行以下 JavaScript 代码:
console.log(document.doctype.publicId)
console.log(document.doctype.systemId)
internalSubset 用于访问文档类型声明中可能包含的额外定义,如下面的例子所示:
<!DOCTYPE html PUBLIC "-// W3C// DTD XHTML 1.0 Strict// EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd"
[<!ELEMENT name (#PCDATA)>] >
对于以上声明, document.doctype.internalSubset 会返回 "<!ELEMENT name (#PCDATA)>" 。HTML 文档中几乎不会涉及文档类型的内部子集,XML 文档中稍微常用一些。
# Document 的变化
Document 类型的更新中唯一跟命名空间无关的方法是 importNode() 。这个方法的用途是从给一个文档中取得一个节点,然后将其导入到另一个文档,使其成为这个文档结构的一部分,需要注意的是,每个节点都有一个 ownerDocument 属性,表示所属的文档,如果调用 appendChild() 时传入的节点属于不同的文档(ownerDocument 属性的值不一致)则会导致错误,但在调用 importNode() 时传入不同文档节点则会返回一个新节点,这个新节点的所有权归当前文档所有。
importNode() 方法跟 cloneNode() 方法类似,同样接收两个参数:要复制的节点和表示是否同时复制子节点的布尔值,返回结果是适合在当前文档中使用的新节点。下面看一个例子:
let newNode = document.importNode(oldNode, true) // 导入节点及所有后代
document.body.appendChild(newNode)
这个方法在 HTML 中使用得并不多,在 XML 文档中的使用会更多一些;
DOM2 View 给 Document 类型增加了新属性 defaultView ,是一个指向拥有当前文档的窗口(或窗格 frame )的指针;
let parentWindow = document.defaultView || document.parentWindow;
# Node 的变化
DOM3 新增了两个用于比较节点的方法: isSameNode() 和 isEqualNode() 。这两个方法都接收一个节点参数,如果这个节点与参考节点相同或相等,则返回 true 。节点相同,意味着引用同一个对象;节点相等,意味着节点类型相同,拥有相等的属性( nodeName 、 nodeValue 等),而且 attributes 和 childNodes 也相等(即同样的位置包含相等的值)。来看一个例子:
let div1 = document.createElement('div')
div1.setAttribute('class', 'box')
let div2 = document.createElement('div')
div2.setAttribute('class', 'box')
console.log(div1.isSameNode(div1)) // true
console.log(div1.isEqualNode(div2)) // true
console.log(div1.isSameNode(div2)) // false
DOM3 也增加了给 DOM 节点附加额外数据的方法。 setUserData() 方法接收 3 个参数:键、值、处理函数,用于给节点追加数据。可以像下面这样把数据添加到一个节点:
document.body.setUserData('name', 'jiegiser', function(){})
然后,可以通过相同的键再取得这个信息,比如:
let value = document.body.getUserData('name')
setUserData() 的处理函数会在包含数据的节点被复制、删除、重命名或导入其他文档的时候执行,可以在这时候决定如何处理用户数据。处理函数接收 5 个参数:表示操作类型的数值( 1 代表复制,2 代表导入, 3 代表删除, 4 代表重命名)、数据的键、数据的值、源节点和目标节点。删除节点时,源节点为 null ;除复制外,目标节点都为 null 。
let div = document.createElement("div");
div.setUserData("name", "Nicholas", function(operation, key, value, src, dest) {
if (operation == 1) {
dest.setUserData(key, value, function() {});
}
});
let newDiv = div.cloneNode(true);
console.log(newDiv.getUserData("name")); // "Nicholas"
# 框架的变化
DOM2 HTML 给 HTMLIFrameElement (即 iframe ,内嵌窗格)类型新增了一个属性,叫 contentDocument 。这个属性包含代表子内嵌窗格中内容的 document 对象的指针。下面的例子展示了如何使用这个属性:
let iframe = document.getElementById("myIframe");
let iframeDoc = iframe.contentDocument;
contentDocument 属性是 Document 的实例,拥有所有文档属性和方法,因此可以像使用其他 HTML 文档一样使用它。还有一个属性 contentWindow ,返回相应窗格的 window 对象,这个对象上有一个 document 属性。所有现代浏览器都支持 contentDocument 和 contentWindow 属性。
# 样式
任何支持 style 属性的 HTML 元素在 JavaScript 中都会有一个对应的 style 属性; CSS 属性名使用连字符表示法,在 JavaScript 中就转换为驼峰大小写形式;但有一个 CSS 属性名不能直接转换,它就是 float 。因为 float 是 JavaScript 的保留字,所以不能用作属性名。DOM2 Style规定它在 style 对象中对应的属性应该是 cssFloat 。
通过 style 属性设置的值也可以通过 style 对象获取。
# DOM 样式属性和方法
DOM2 Style 规范也在 style 对象上定义了一些属性和方法。这些属性和方法提供了元素 style 属性的信息同时,也可以修改样式,如下:
- cssText ,包含 style 属性中的 CSS 代码。
- length ,应用给元素的 CSS 属性数量。
- parentRule ,表示 CSS 信息的 CSSRule 对象。
- getPropertyCSSValue(propertyName) ,返回包含 CSS属性 propertyName 值的 CSSValue 对象(已废弃)。
- getPropertyPriority(propertyName) ,如果 CSS 属性 propertyName 使用了 !important 则返回 "important" ,否则返回空字符串。
- getPropertyValue(propertyName) ,返回属性 propertyName 的字符串值。
- item(index) ,返回索引为 index 的 CSS 属性名。
- removeProperty(propertyName) ,从样式中删除 CSS 属性 propertyName 。
- setProperty(propertyName, value, priority) ,设置 CSS 属性 propertyName 的值为 value ,priority 是 "important" 或空字符串。
过 cssText 属性可以存取样式的 CSS 代码。在读模式下, cssText 返回 style 属性 CSS代码在浏览器内部的表示。在写入模式下,给 cssText 赋值会重写整个 style 属性的值,意味着之前通过 style 属性设置的属性都会丢失。
ength 属性是跟 item() 方法一起配套迭代 CSS 属性用的。此时, style 对象实际上变成了一个集合,也可以用中括号代替 item() 取得相应位置的 CSS 属性名,如下所示:
for (let i = 0, len = myDiv.style.length; i < len; i ++) {
console.log(myDiv.style.item(i)) // 或者 myDiv.style[i]
}
使用中括号或者 item() 都可以取得相应位置的 CSS 属性名( "background-color" ,不是 "backgroundColor" )。这个属性名可以传给 getPropertyValue() 以取得属性的值,如下面的例子所示:
let prop, value, i, len;
for (i = 0, len = myDiv.style.length; i < len; i++) {
prop = myDiv.style[i]; // 或者用 myDiv.style.item(i)
value = myDiv.style.getPropertyValue(prop);
console.log(`prop: ${value}`);
}
# 计算的样式
style 对象中包含支持 style 属性的元素为这个属性设置的样式信息,但不包含从其他样式表层叠继承的同样影响该元素的样式信息。DOM2 Style在 document.defaultView 上增加了 getComputedStyle() 方法。这个方法接收两个参数:要取得计算样式的元素和伪元素字符串(如 ":after" )。如果不需要查询伪元素,则第二个参数可以传 null 。 getComputedStyle() 方法返回一个 CSSStyleDeclaration 对象(与 style 属性的类型一样),包含元素的计算样式。假设有如下 HTML 页面:
<!DOCTYPE html>
<html>
<head>
<title>Computed Styles Example</title>
<style type="text/css">
#myDiv {
background-color: blue;
width: 100px;
height: 200px;
}
</style>
</head>
<body>
<div id="myDiv" style="background-color: red; border: 1px solid black"></div>
</body>
</html>
这里的 div 元素从文档样式表( style 元素)和自己的 style 属性获取了样式。此时,这个元素的 style 对象中包含 backgroundColor 和 border 属性,但不包含(通过样式表规则应用的)width 和 height 属性。下面的代码从这个元素获取了计算样式:
let myDiv = document.getElementById("myDiv");
let computedStyle = document.defaultView.getComputedStyle(myDiv, null);
console.log(computedStyle.backgroundColor); // "red"
console.log(computedStyle.width); // "100px"
console.log(computedStyle.height); // "200px"
console.log(computedStyle.border); // "1px solid black"(在某些浏览器中)
关于计算样式要记住一点,在所有浏览器中计算样式都是只读的,不能修改 getComputedStyle() 方法返回的对象。而且,计算样式还包含浏览器内部样式表中的信息。因此有默认值的 CSS属性会出现在计算样式里。例如,visibility 属性在所有浏览器中都有默认值,但这个值因实现而不同。有些浏览器会把 visibility 的默认值设置为 "visible" ,而另一些将其设置为 "inherit" 。不能假设 CSS属性的默认值在所有浏览器中都一样。如果需要元素具有特定的默认值,那么一定要在样式表中手动指定。
# 操作样式表
CSSStyleSheet 类型表示 CSS 样式表包括使用 link 元素和通过 style 元素定义的样式表。CSSStyleSheet 类型的实例则是一个只读对象(只有一个属性例外)。CSSStyleSheet 类型继承 StyleSheet ,后者可用作非CSS样式表的基类。以下是 CSSStyleSheet 从 StyleSheet 继承的属性。
- disabled ,布尔值,表示样式表是否被禁用了(这个属性是可读写的,因此将它设置为 true会禁用样式表)。
- href ,如果是使用 link 包含的样式表,则返回样式表的 URL,否则返回 null 。
- media ,样式表支持的媒体类型集合,这个集合有一个 length 属性和一个 item() 方法,跟所有 DOM 集合一样。同样跟所有 DOM 集合一样,也可以使用中括号访问集合中特定的项。如果样式表可用于所有媒体,则返回空列表。
- ownerNode ,指向拥有当前样式表的节点,在 HTML 中要么是 link 元素要么是 style 元素(在 XML 中可以是处理指令)。如果当前样式表是通过 @import 被包含在另一个样式表中,则这个属性值为 null 。
- parentStyleSheet ,如果当前样式表是通过 @import 被包含在另一个样式表中,则这个属性指向导入它的样式表。
- title , ownerNode 的 title 属性。
- type ,字符串,表示样式表的类型。对 CSS 样式表来说,就是 "text/css" 。
上述属性里除了 disabled ,其他属性都是只读的。除了上面继承的属性, CSSStyleSheet 类型还支持以下属性和方法。
- cssRules ,当前样式表包含的样式规则的集合。
- ownerRule ,如果样式表是使用 @import 导入的,则指向导入规则;否则为 null 。
- deleteRule(index) ,在指定位置删除 cssRules 中的规则。
- insertRule(rule, index) ,在指定位置向 cssRules 中插入规则
document.styleSheets 表示文档中可用的样式表集合。这个集合的 length 属性保存着文档中样式表的数量,而每个样式表都可以使用中括号或 item() 方法获取。来看这个例子:
let sheet = null
for (let i = 0, len = document.styleSheets.length; i < len; i++) {
sheet = document.styleSheets[i]
console.log(sheet.href)
}
# CSS 规则
CSSRule 类型表示样式表中的一条规则。这个类型也是一个通用基类,很多类型都继承它,但其中最常用的是表示样式信息的 CSSStyleRule (其他 CSS 规则还有 @import 、 @font-face 、@page 和 @charset 等,不过这些规则很少需要使用脚本来操作)。以下是 CSSStyleRule 对象上可用的属性。
- cssText ,返回整条规则的文本。这里的文本可能与样式表中实际的文本不一样,因为浏览器内部处理样式表的方式也不一样。Safari 始终会把所有字母都转换为小写。
- parentRule ,如果这条规则被其他规则(如 @media )包含,则指向包含规则,否则就是 null 。
- parentStyleSheet ,包含当前规则的样式表。
- selectorText ,返回规则的选择符文本。这里的文本可能与样式表中实际的文本不一样,因为浏览器内部处理样式表的方式也不一样。这个属性在 Firefox、Safari、Chrome 和 IE 中是只读的,在 Opera 中是可以修改的。
- style ,返回 CSSStyleDeclaration 对象,可以设置和获取当前规则中的样式。
- type ,数值常量,表示规则类型。对于样式规则,它始终为 1 。
# 创建规则
DOM 规定,可以使用 insertRule() 方法向样式表中添加新规则。这个方法接收两个参数:规则的文本和表示插入位置的索引值。下面是一个例子:
sheet.insertRule("body { background-color: silver }", 0); // 使用 DOM 方法
# 删除规则
支持从样式表中删除规则的 DOM 方法是 deleteRule() ,它接收一个参数:要删除规则的索引。要删除样式表中的第一条规则,可以这样做:
sheet.deleteRule(0); // 使用 DOM 方法
# 元素大小
- 偏移量 第一组属性涉及偏移尺寸(offset dimensions),包含元素在屏幕上占用的所有视觉空间。元素在页面上的视觉空间由其高度和宽度决定,包括所有内边距、滚动条和边框(但不包含外边距)。以下 4 个属性用于取得元素的偏移尺寸。
- offsetHeight ,元素在垂直方向上占用的像素尺寸,包括它的高度、水平滚动条高度(如果可见)和上、下边框的高度。
- offsetLeft ,元素左边框外侧距离包含元素左边框内侧的像素数。
- offsetTop ,元素上边框外侧距离包含元素上边框内侧的像素数。
- offsetWidth ,元素在水平方向上占用的像素尺寸,包括它的宽度、垂直滚动条宽度(如果可见)和左、右边框的宽度。
其中, offsetLeft 和 offsetTop 是相对于包含元素的,包含元素保存在 offsetParent 属性中。offsetParent 不一定是 parentNode 。比如, td 元素的 offsetParent 是作为其祖先的 table 元素,因为 table 是节点层级中第一个提供尺寸的元素。
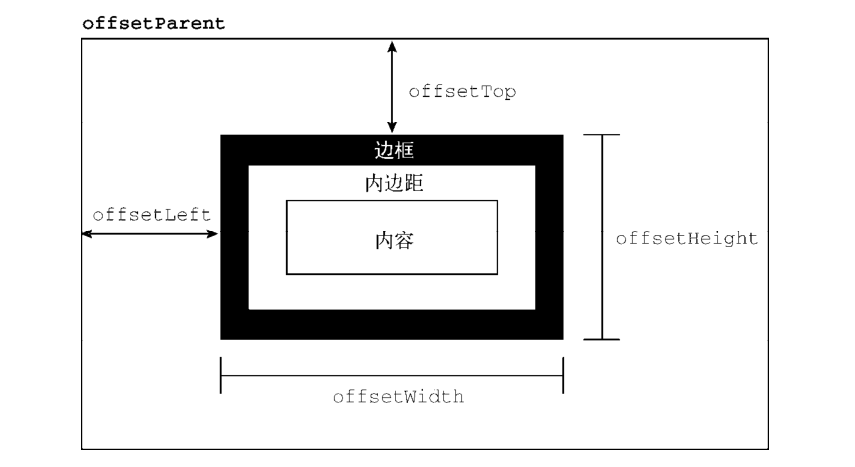
要确定一个元素在页面中的偏移量,可以把它的 offsetLeft 和 offsetTop 属性分别与 offsetParent 的相同属性相加,一直加到根元素。下面是一个例子:
function getElementLeft(element) {
let actualLeft = element.offsetLeft
let current = element.offsetParent
while(current !== null) {
actualLeft += current.offsetLeft
current = current.offsetParent
}
return actualLeft
}
function getElementTop(element) {
let actualTop = element.offsetTop
let current = element.offsetParent
while(current !== null) {
actualTop += current.offsetTop
current = current.offsetParent
}
return actualTop
}
对于使用 CSS 布局的简单页面,这两个函数是很精确的。而对于使用表格和内嵌窗格的页面布局,它们返回的值会因浏览器不同而有所差异,因为浏览器实现这些元素的方式不同。一般来说,包含在 div 元素中所有元素都以 body 为其 offsetParent ,因此 getElementleft() 和 getElementTop() 返回的值与 offsetLeft 和 offsetTop 返回的值相同。
所有这些偏移尺寸属性都是只读的,每次访问都会重新计算。因此,应该尽量减少查询它们的次数。比如把查询的值保存在局量中,就可以避免影响性能。
- 客户端尺寸
元素的客户端尺寸(client dimensions)包含元素内容及其内边距所占用的空间。客户端尺寸只有两个相关属性: clientWidth 和 clientHeight 。其中,clientWidth 是内容区宽度加左、右内边距宽度, clientHeight 是内容区高度加上、下内边距高度。
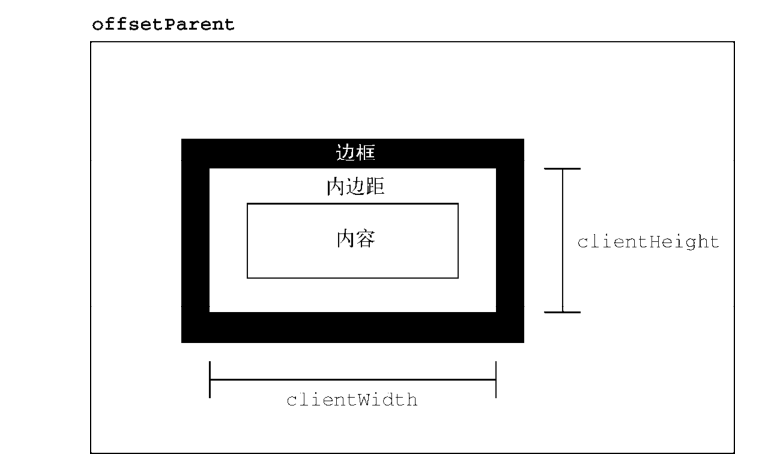
客户端尺寸实际上就是元素内部的空间,因此不包含滚动条占用的空间。这两个属性最常用于确定浏览器视口尺寸,即检测 document.documentElement 的 clientWidth 和 clientHeight 。这两个属性表示视口( html 或 body 元素)的尺寸。
与偏移尺寸一样,客户端尺寸也是只读的,而且每次访问都会重新计算。
- 滚动尺寸
提供了元素内容滚动距离的信息。有些元素,比如 html 无须任何代码就可以自动滚动,而其他元素则需要使用 CSS 的 overflow 属性令其滚动。滚动尺寸相关的属性有如下 4 个。
- scrollHeight ,没有滚动条出现时,元素内容的总高度。
- scrollLeft ,内容区左侧隐藏的像素数,设置这个属性可以改变元素的滚动位置。
- scrollTop ,内容区顶部隐藏的像素数,设置这个属性可以改变元素的滚动位置。
- scrollWidth ,没有滚动条出现时,元素内容的总宽度。
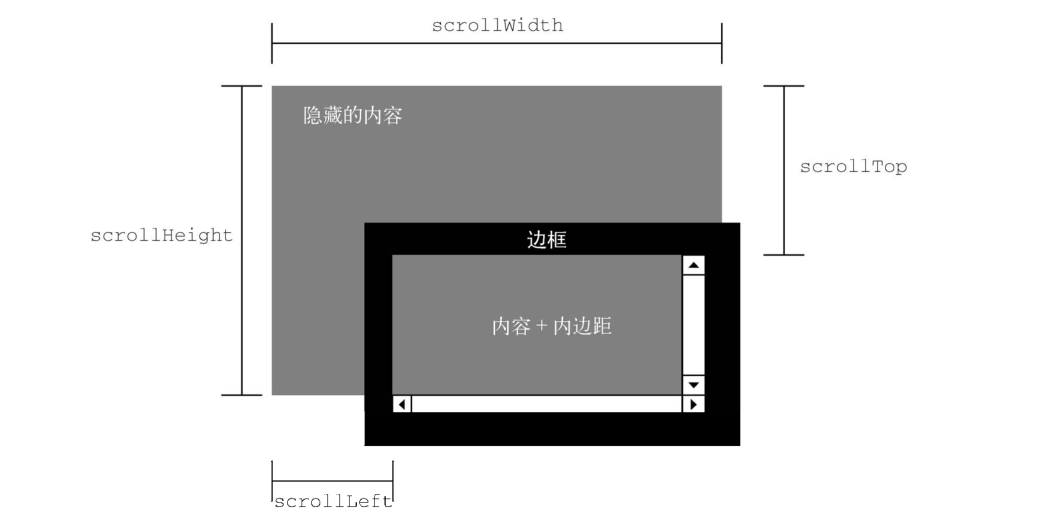
scrollWidth 和 scrollHeight 可以用来确定给定元素内容的实际尺寸。例如,html 元素是浏览器中滚动视口的元素。因此, document.documentElement.scrollHeight 就是整个页面垂直方向的总高度。
对于不包含滚动条的页面 scrollWidth 和 scrollHeight 与 clientWidth 和 clientHeight 之间的关系并不十分不清。如果文档尺寸超过视口尺寸,则在所有主流浏览器中这两对属性都不相等,scrollWidth 和 scollHeight 等于文档内容的宽度,而 clientWidth 和 clientHeight 等于视口的大小。
scrollLeft 和 scrollTop 属性可以用于确定当前元素滚动的位置,或者用于设置它们的滚动位置。元素在未滚动时,这两个属性都等于 0 。如果元素在垂直方向上滚动,则 scrollTop 会大于 0 ,表示元素顶部不可见区域的高度。如果元素在水平方向上滚动,则 scrollLeft 会大于 0 ,表示元素左侧不可见区域的宽度。因为这两个属性也是可写的,所以把它们都设置为 0 就可以重置元素的滚动位置。
下面这个函数检测元素是不是位于顶部,如果不是则滚动到顶部
function scrollTop(element) {
if (element.scrollTop !== 0) {
element.scrollTop = 0
}
}
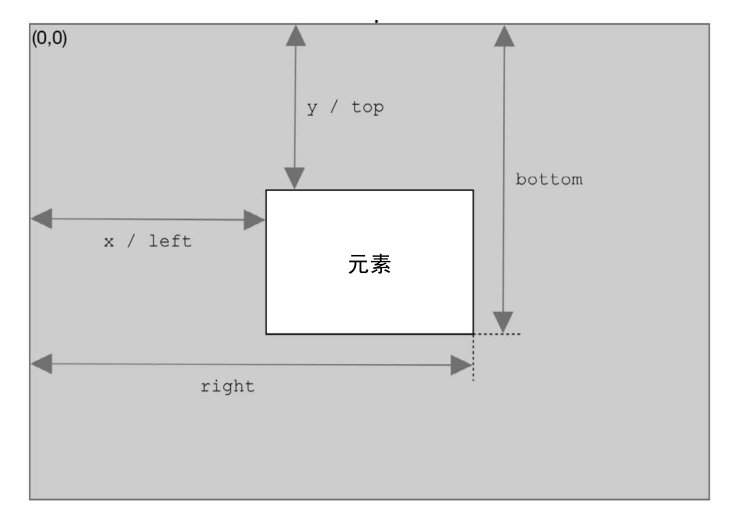
- 确定元素大小
浏览器在每个元素上都暴露了 getBoundingClientRect() 方法,返回一个 DOMRect 对象,包含 6 个属性: left 、 top 、 right 、 bottom 、 height 和 width 。这些属性给出了元素在页面中相对于视口的位置
# 遍历
# NodeIterator
可以通过 document.createNodeIterator() 方法创建其实例。这个方法接收以下 4 个参数。
- root ,作为遍历根节点的节点。
- whatToShow ,数值代码,表示应该访问哪些节点。
- filter,NodeFilter 对象或函数,表示是否接收或跳过特定节点。
- entityReferenceExpansion ,布尔值,表示是否扩展实体引用。这个参数在 HTML 文档中没有效果,因为实体引用永远不扩展。
whatToShow 参数是一个位掩码,通过应用一个或多个过滤器来指定访问哪些节点。这个参数对应的常量是在 NodeFilter 类型中定义的。
- NodeFilter.SHOW_ALL ,所有节点。
- NodeFilter.SHOW_ELEMENT ,元素节点。
- NodeFilter.SHOW_ATTRIBUTE ,属性节点。由于 DOM的结构,因此实际上用不上。
- NodeFilter.SHOW_TEXT ,文本节点。
- NodeFilter.SHOW_CDATA_SECTION ,CData 区块节点。不是在 HTML 页面中使用的。
- NodeFilter.SHOW_ENTITY_REFERENCE ,实体引用节点。不是在 HTML 页面中使用的。
- NodeFilter.SHOW_ENTITY ,实体节点。不是在 HTML 页面中使用的。
- NodeFilter.SHOW_PROCESSING_INSTRUCTION ,处理指令节点。不是在 HTML 页面中使用的。
- NodeFilter.SHOW_COMMENT ,注释节点。
- NodeFilter.SHOW_DOCUMENT ,文档节点。
- NodeFilter.SHOW_DOCUMENT_TYPE ,文档类型节点。
- NodeFilter.SHOW_DOCUMENT_FRAGMENT ,文档片段节点。不是在 HTML 页面中使用的。
- NodeFilter.SHOW_NOTATION ,记号节点。不是在 HTML 页面中使用的。
这些值除了 NodeFilter.SHOW_ALL 之外,都可以组合使用。比如,可以像下面这样使用按位或操作组合多个选项:
let whatToshow = NodeFilter.SHOW_ELEMENT | NodeFilter.SHOW_TEXT
createNodeIterator() 方法的 filter 参数可以用来指定自定义 NodeFilter 对象,或者一个作为节点过滤器的函数。 NodeFilter 对象只有一个方法 acceptNode() ,如果给定节点应该访问就返回 NodeFilter.FILTER_ACCEPT ,否则返回 NodeFilter.FILTER_SKIP 。因为 NodeFilter 是一个抽象类型,所以不可能创建它的实例。只要创建一个包含 acceptNode() 的对象,然后把它传给 createNodeIterator() 就可以了。以下代码定义了只接收 p 元素的节点过滤器对象:
let filter = {
acceptNode(node) {
return node.tagName.toLowerCase() === 'p' ? NodeFilter.FILTER_ACCEPT : NodeFilter.FILTER_SKIP
}
}
let iterator = document.createNodeIterator(root, NodeFilter.SHOW_ELEMENT, filter, false)
filter 参数还可以是一个函数,与 acceptNode() 的形式一样,如下面的例子所示:
let filter = function(node) {
return node.tagName.toLowerCase() === 'p' ? NodeFilter.FILTER_ACCEPT : NodeFilter.FILTER_SKIP
}
let iterator = document.createNodeIterator(root, NodeFilter.SHOW_ELEMENT, filter, false)
如果不需要指定过滤器,则可以给这个参数传入 null。如下代码,遍历所有节点的 NodeIterator:
let iterator = document.createNodeIterator(document, NodeFilter.SHOW_ALL, null, false)
NodeIterator 的两个主要方法是 nextNode() 和 previousNode() 。 nextNode() 方法在 DOM 子树中以深度优先方式进前一步,而 previousNode() 则是在遍历中后退一步。创建 NodeIterator 对象的时候,会有一个内部指针指向根节点,因此第一次调用 nextNode() 返回的是根节点。当遍历到达 DOM 树最后一个节点时, nextNode() 返回 null 。 previousNode() 方法也是类似的。当遍历到达 DOM 树最后一个节点时,调用 previousNode() 返回遍历的根节点后,再次调用也会返回 null 。
比如下面的 html :
<div id="div1">
<p><b>Hello</b> world!</p>
<ul>
<li>List item 1</li>
<li>List item 2</li>
<li>List item 3</li>
</ul>
</div>
遍历 div 元素内部的所有元素:
let div = document.getElementById('div1')
let iterator = document.createNodeIterator(div, NodeFilter.SHOW_ELEMENT, null, false)
let node = iterator.nextNode()
while(node !== null) {
console.log(node.tagName); // 输出标签名
node = iterator.nextNode()
}
遍历 li 元素,传入一个过滤器:
let div = document.getElementById('div1')
let filter = function(node) {
return node.tagName.toLowerCase() === 'li' ? NodeFilter.FILETER_ACCEPT : NodeFilter.FILTER_SHIP
}
let iterator = document.createNodeIterator(div, NodeFilter,SHOW_ELEMENT, filter, false)
let node = iterator.nextNode()
while(node !== null) {
console.log(node.tagName)
node = iterator.nextNode()
}
# TreeWalker
TreeWalker 是 NodeIterator 的高级版。除了包含同样的 nextNode() 、 previousNode() 方法,TreeWalker 还添加了如下在 DOM 结构中向不同方向遍历的方法。
- parentNode() ,遍历到当前节点的父节点。
- firstChild() ,遍历到当前节点的第一个子节点。
- lastChild() ,遍历到当前节点的最后一个子节点。
- nextSibling() ,遍历到当前节点的下一个同胞节点。
- previousSibling() ,遍历到当前节点的上一个同胞节点。
TreeWalker 对象要调用 document.createTreeWalker() 方法来创建,这个方法接收与 document.createNodeIterator() 同样的参数;不同的是,节点过滤器( filter )除了可以返回 NodeFilter.FILTER_ACCEPT 和 NodeFilter.FILTER_SKIP ,还可以返回 NodeFilter.FILTER_REJECT 。在使用 NodeIterator 时, NodeFilter.FILTER_SKIP 和 NodeFilter.FILTER_REJECT 是一样的。但在使用 TreeWalker 时, NodeFilter.FILTER_SKIP 表示跳过节点,访问子树中的下一个节点,而 NodeFilter.FILTER_REJECT 则表示跳过该节点以及该节点的整个子树。
下面的代码是访问 li 元素:
let div = document.getElementById("div1");
let walker = document.createTreeWalker(div, NodeFilter.SHOW_ELEMENT, null, false);
walker.firstChild(); // 前往<p>
walker.nextSibling(); // 前往<ul>
let node = walker.firstChild(); // 前往第一个<li>
while (node !== null) {
console.log(node.tagName);
node = walker.nextSibling();
}
reeWalker 类型也有一个名为 currentNode 的属性,表示遍历过程中上一次返回的节点(无论使用的是哪个遍历方法)。可以通过修改这个属性来影响接下来遍历的起点,如下面的例子所示:
let node = walker.nextNode()
console.log(node === walker.currentNode) // true
walker.currentNode = document.body // 修改起点
相比于 NodeIterator , TreeWalker 类型为遍历 DOM提供了更大的灵活性。